
 17
17






Meta today presented V-JEPA 2, a 1.2-billion-parameter world model trained primarily on video to support understanding, prediction, and planning in robotic systems.
Built on the Joint Embedding Predictive Architecture (JEPA), the design is created to help robotics and other “& ldquo; AI representatives & rdquo; navigate unfamiliar environments and jobs with limited domain-specific training.V-JEPA 2 follows a two-stage training procedure all without extra human annotation.
In the first, self-supervised phase, the model learns from over 1 million hours of video and 1 million images, catching patterns of physical interaction.
The 2nd stage introduces action-conditioned knowing utilizing a small set of robotic control information (about 62 hours), enabling the model to consider representative actions when predicting outcomes.
This makes the design usable for planning and closed-loop control tasks.Meta stated it has actually already checked this new model on robotics in its laboratories.
Meta reports that V-JEPA 2 performs well on common robotic tasks like and pick-and-place, utilizing vision-based goal representations.
For easier jobs such as pick and place, the system creates prospect actions and examines them based upon forecasted outcomes.
For tougher tasks, such as getting an object and putting it in the ideal spot, V-JEPA2 utilizes a series of visual subgoals to direct behavior.In internal tests, Meta said the design revealed appealing capability to generalize to new things and settings, with success rates varying from 65% to 80% on pick-and-place jobs in previously unseen environments.“& ldquo; We think world models will usher a brand-new age for robotics, making it possible for real-world AI representatives to aid with chores and physical tasks without requiring astronomical quantities of robotic training data,” & rdquo; said Meta & rsquo; s chief AI researcher Yann LeCun.Although V-JEPA 2 shows improvements over previous designs, Meta AI stated there remains a noticeable space in between model and human performance on these benchmarks.
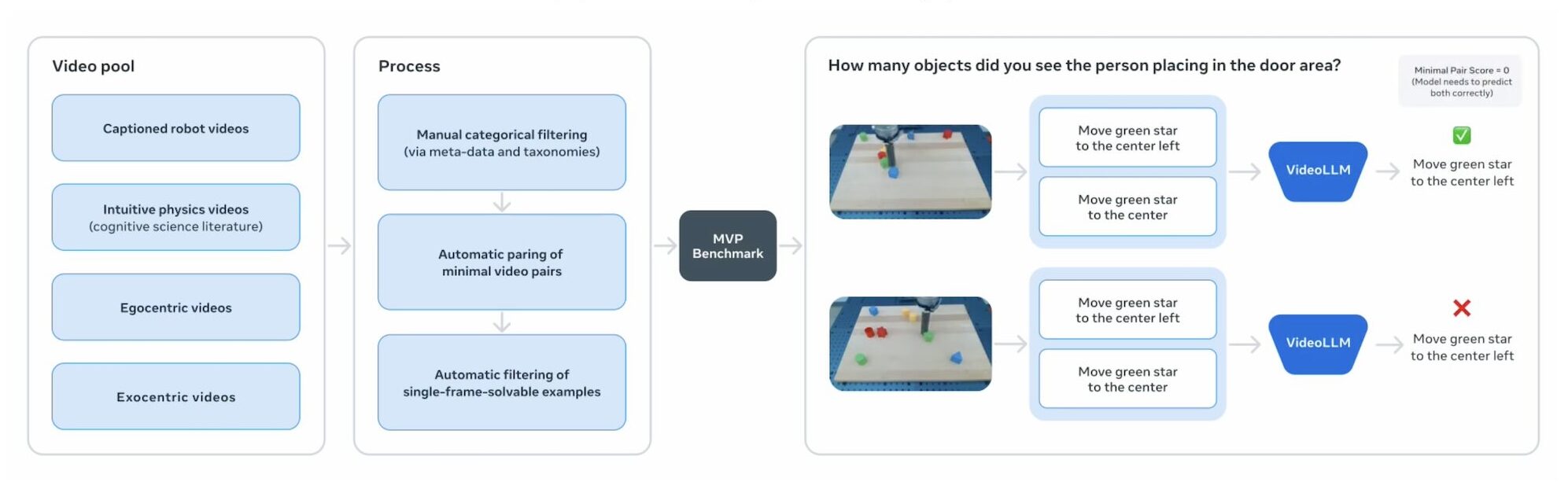
Meta suggests this points to the need for designs that can run throughout numerous timescales and methods, such as incorporating audio or tactile information.To examine development in physical understanding from video, Meta is likewise launching the following 3 criteria: IntPhys 2: examines the design’& rsquo; s ability to compare physically possible and implausible scenarios.MVPBench: tests whether models rely on real understanding instead of dataset faster ways in video question-answering.
CausalVQA: analyzes thinking about cause-and-effect, anticipation, and counterfactuals.The V-JEPA 2 code and design checkpoints are offered for industrial and research use, with Meta aiming to encourage more comprehensive exploration of world designs in robotics and embodied AI.Meta signs up with other tech leaders in developing their own world designs.
Google DeepMind has actually been developing its own version, Genie, which can imitate whole 3D environments.
And World Labs, a startup established by Fei-Fei Li, raised $230 million to develop big world models.The post Meta V-JEPA 2 world design uses raw video to train robots appeared first on The Robot Report.

